Introduction
Our goal for the Human-Robot Interaction class final project is to study how an emotional robot should behave when interacting with humans, and to implement one using multimodal recognition (based on voice and face).
We are using the iCat robot by Philips, which is capable of expressing a great richness of expressions:

Downloads
| Source code | emospeech.zip (125 KB) |
| Slides | emospeech.ppt (484 KB) |
| Video demonstration | emospeech.avi (11.5 MB) |
Study
Speech emotion recognition
The general architecture for a speech emotion recognition system has three steps (next figure):
- A speech processing system extract some appropriate quantities from the signal, such as the pitch or the energy,
- These quantities are summarized into a reduced set of features,
- A classifier learns in a supervised manner with example data how to associate the features to the emotions.
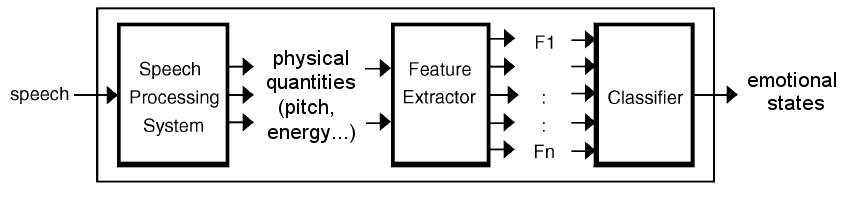
So the big question is how to choose the features.
Approaches
Local approach: the Tilt model
References:- P. Taylor, The Tilt Intonation Model, 1998
- Edimburgh Speech Tools (EST) library documentation
The first approach we considered was based on the Tilt model. It is based on intonation events, which corresponds to some vowels (next figure).
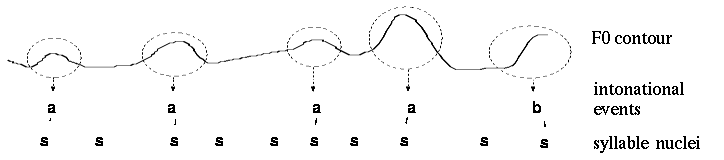
These intonation events can be well described by the RFC model (Rise/Fall/Connection model, next figure). It describes fall and rise lengths and amplitudes. This is very interesting for emotion recognition, because the manner how people insist on vowels conveys a lot of information about the emotional state.
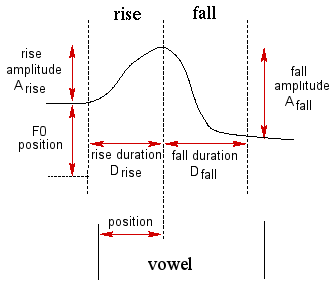
Actually the RFC model is often simplified into the Tilt model, that reduces the number of parameters and preserves the richness of expression:
- Amplitude:
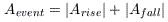
- Duration:

- Tilt (shape):
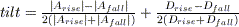
Though the RFC and Tilt models were implemented in some speech processing libraries (e.g. Edinburgh Speech Tools (EST)), the automatic intonation event labeler was not provided. It involves careful training of HMMs, and was too complicated to do for this project.
That's why we decided to study another type of approaches.
Global approach
The idea here is to extract global features from the signal to classify them. These are based on acoustic quantities:
- Pitch: average, variance, min, max, range, ...
- Energy: average, variance, min, max, range, average/variance, ...
- Other: pace, voiced percentage, ...
Then these features are directly classified into emotional states. The classifier should preferably be able to take a large number of input features, and do explicit or implicit features selection.
This is less precise than the local approaches, but it is a lot more simple too.
However, we still need a set of examples data in order to train the classifier. Unfortunately we didn't manage to find an emotional speech database in english on the web. We were planning to use the data resulting from our study in order to create an example base, but unfortunately the results were not those expected and the collected data not rich enough regarding emotions.
So we simplified a little bit the principle, by using a limited set of features (voiced percentage, pitch average and variance, energy average and variance, and the energy variance normalized by the average), and a very simple classification algorithm.
At first, we did want to use a decision tree to classify emotional states, i.e. a set of rules like:
if ((pitch_avg < 120) && (pitch_var < 40) && (energy_avg < 14000)) emotion = eSad
So we recorded our voice with the different emotions, analyzed it and plotted it according to the features:
We can notice that some features seems to be discriminative:
- Pitch average
- Percentage voiced, but it is more related to the pitch tracker performance than really unvoiced frames, so maybe this is not very reliable
- Energy average, but it depends on the microphone, the volume, the distance to the microphone, and even the context, so it is not very reliable neither
So we decided to use another simple classifer: nearest neighbor with Mahalanobis distance. From the small set of training data we extract the average and variance for each feature. Then, to classify an utterance, we compute its distance to each of the cluster centers, using the Mahalanobis distance (in this simple case, this is the euclidian distance with each component normalized by the variance).
Implementation
Architecture
We used Edinburgh Speech Tools (EST) library in order to do pitch tracking and audio acquisition.
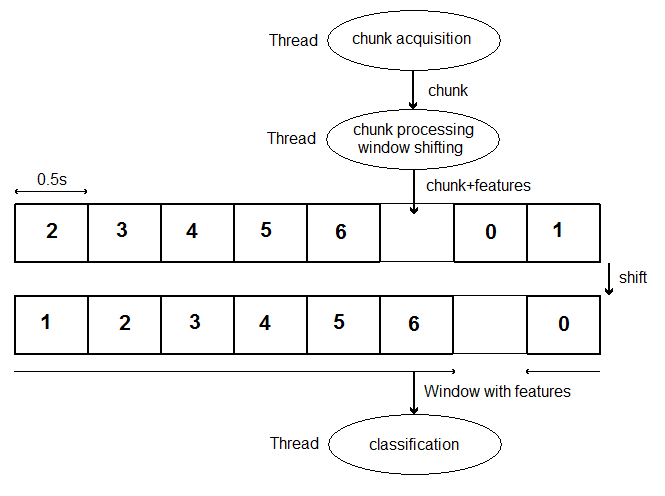
The classificaion is operated online. Next figure presents the global architecture that allows that. We had only access to a blocking function that acquires a given time of sound. So this function was run in a separate thread, keeping getting chunk of data. Another thread was synchronized with in order to organize the data in a circular buffer, and to process the data to extract features. Then the main thread is using the full window in order to classify the emotion. It can classify data whenever it want, except that if there was no new data since the last time it classified the emotion, it is blocked until data is updated.
The program
You can download the source code here.
To compile it, you need Edinburgh Speech Tools (EST) Library 1.2.96. It compiles under Linux. We tried to compile it with Windows, but eventually gave up (though it seems it was possible with previous versions).
All parameters can be changed in an XML configuration file, or in the Command Line Interpreter:
./emospeech_test -nChunks=20 -chunkLength=0.5 -acquisFreq=22050Possible parameters can be listed with description with the
--help parameter.
The learned data for recognition are given by the option configLearn:
./emospeech_test -configLearn=cyril2.xmlThe learning phase wasn't completely automated. In order to learn new data, you have use the
data.csv file which in which are recorded the features when classifying. You open it in MSOffice or OOCalc (though it is tab-separated values instead of comma-separated values) in order to compute centers and variances for each feature and each emotion, and put them in a learned configuration file (like cyril2.xml).
The first sound window is recorded too in the file out.raw. You can test it (e.g. if gain is ok) with the command na_play from EST.
Results
As we were lacking data, and time after realizing that the data collected during the study were not usable, we only tested for one person. Performance actually depends on the emotion. Sad and Happy states are always recognized, but Angry and Neutral are more sensitive (~60%). The thing is that if you want to make it work, you can. But you want to trick it, you can very easily too. More training data, and duplicating emotions for men and women would improve the multi-speaker abilities. Then more features and a better learning algorithm would too.
You can download here a video demonstration.
To conclude, the fact that we were not able to compile the speech processing library with Windows is one of the reasons why we didn't implement the multimodal recognition. It would have been possible to have speech and facial recognition running on two separate computers and communicate through network, but anyway the facial recognition part was not running inline.